Saiba como desbravar dados complexos no Databricks em uma jornada de leitura e manipulação de arquivos JSON usando SQL
Em um mundo com múltiplas formas de
armazenar dados devemos ser capazes de consumir a informação independe da forma como ela está guardada. Um exemplo muito comum são arquivos Json. Este formato estruturado de texto é uma notação que permite transferência de dados seguindo um padrão específico, que pode ou não se repetir para todos os dados.
No ambiente
Databricks ler esse tipo de arquivo geralmente é feito usando pyspark com uma notação similar a:
Para dados com estrutura bem definida, o pyspark consegue inferir o schema e ler o Json.
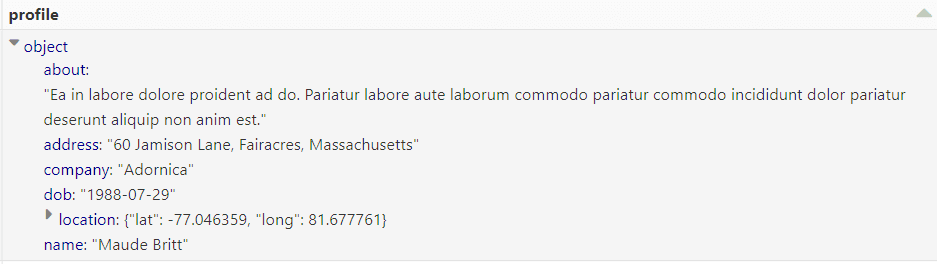
Perceba que temos um Json aninhado na coluna ‘profile’.
E a coluna ‘roles’ é um array
Existe uma farta documentação na internet sobre como ler e manipular arquivos usando pyspark. Entretanto, há uma alternativa para ler os arquivos usando SQL. Algumas vantagens de usá-la seriam uma sintaxe mais parecida com a natural, o que torna a compreensão do código mais fácil. Por ser uma linguagem existente desde 1974 e altamente difundida é mais fácil encontrar pessoas para dar manutenção e para desenvolver cargas de com o SQL.
O formato padrão para ler os arquivos é simplesmente:
Contudo, essa forma de leitura funciona muito bem para arquivos com schema estabelecido, como parquet ou Json com estruturas idênticas para todos os dados. Detalhe importante é que o comando acima não suporta declaração de schema. Quando a estrutura não for pré-determinada ainda é possível ler o arquivo mas demanda um pouco mais de detalhes.
Primeiramente vamos “setar” uma configuração para guardar o caminho a ser usado caso você tenha a necessidade de usar um caminho variável
Isso não é necessário se o caminho for fixo.
Em seguida, vamos ler o nosso arquivo declarando o schema:
Neste exemplo estamos carregando os dados a partir de path e os inserindo em uma tabela temporária. Por que uma temporária em vez de uma tabela normal? Bem, é factível, mas uma tabela externa em databricks não é uma tabela delta. Nós perdemos todas as vantagens de ter uma delta se gravarmos diretamente do arquivo. A ideia aqui é carregar os dados para uma temporária e então salvar esses dados da temporária para uma delta.
Como podemos observar é possível acessar os dados aninhados usando a notação de ponto. Neste momento temos acesso completo aos dados do arquivo. Todas as manipulações DML suportadas pelo Spark SQL estão a sua disposição. Agora o céu é o limite. Divirta-se!