

escrito por Kristy Noms
6 minutos de leitura

Nesse post, iremos falar sobre o projeto realizado em um cliente ilegra, uma indústria de implementos agrícolas, no ambiente de banco de dados SQL Server.
Havia a necessidade de realizarmos upgrade da versão 2014 para a 2019 devido ao lifecycle de suporte da Microsoft. Porém, junto a isso, o cliente queria melhorar a disponibilidade e resiliência de seu ambiente de banco de dados.
Tendo servidores em sites geograficamente distantes para melhorar seu plano de Disaster Recovery, mapeamos as seguintes opções de arquitetura no início do projeto.
Cenário antigo

Havia dois servidores usando um storage compartilhado, com a feature de Failover Cluster do SQL Server. Essa disponibilidade é à nível de instance; caso um servidor tenha problemas, os recursos são direcionados para o outro. Não há possibilidade do node passivo permitir leitura e, no caso de problema no storage, o ambiente ficaria indisponível. Além disso, os dois servidores estavam no mesmo datacenter.
Por ser passivo o segundo node, não era cobrado licenciamento.
Primeiro cenário proposto: Failover Cluster + AlwaysON


Nesse cenário, a proposta seria manter o Failover Cluster no Site A, adicionando um servidor no Site B para usar a feature de AlwaysON. Se ocorresse um evento de falha no Site A, seria realizado o failover das bases para o Site B. O AlwaysON atua no nível de disponibilidade das bases, ou seja, os dados das bases estão nos dois storages – sendo somente feita a replicação dos dados pela rede (log de transação).
O Site B fica disponível para leitura, enquanto o Site A para leitura e escrita.
Porém, nessa arquitetura, seria necessário adquirir mais uma licença de SQL para o terceiro servidor.
Segundo Cenário proposto: Somente AlwaysON


A segunda alternativa seria a utilização de duas máquinas já disponíveis no cliente, montando um cluster de AlwaysON. Uma delas vai para o Site B, garantindo a alta disponibilidade das bases – caso necessário, poderia ser habilitado o parâmetro de direcionamento de leitura para o node passivo.
Cada node usa o seu próprio storage; porém, como o segundo node não é mais passivo, teria a necessidade de licenciar todos os cores de cpu da máquina no Site B.
Terceiro cenário proposto: Failover Cluster sem o compartilhamento de storage

Nessa possibilidade, seria mantida a configuração inicial, mas sem o uso de storage compartilhado e com um node no outro Site.
Através da feature Storage Spaces Direct, do Windows Server, é feito um pool com os discos disponíveis para ambos os servidores. Assim, ele cria uma stack única de discos com alta disponibilidade, visível entre os nodes do cluster, quase como um storage compartilhado virtualizado pelo Windows.
Foram levados em consideração os seguintes requisitos para a escolha:
+++ Custos de licenciamento;
+++ Alta disponibilidade;
+++ Ter os servidores em sites geograficamente distantes.
Com isso, foi escolhido o cenário 3, que nos permitia manter um servidor em cada site com seu storage e com a replicação dos dados. Em caso de falha de um storage, o banco permanece online no outro, sem impactar em custo de licenciamento extra, já que o segundo node é mantido como passivo.
Esta é uma feature nativa do Windows Server a partir da versão 2016. Funciona como um RAID-1 otimizado para manter a alta disponibilidade dos discos. No entanto, “perdemos” uma boa parte do storage nesse modo – se eu preciso de 1 TB para dados, são necessários 2 TB para o Windows.
Dessa forma, temos sempre uma cópia do dado em todos os servidores envolvidos.
O interessante é que ele não grava o dado simplesmente em outro drive, mas divide a informação em chunks menores e escreve igualmente em todos os discos do pool. Se um disco é perdido, ele garante a disponibilidade.

+++ Perda de um disco não compromete o ambiente.

+++ Perda de um servidor não gera indisponibilidade

Sem entrar em detalhes técnicos de cada etapa, foram realizadas as seguintes atividades:
+++ Instalação do failover clustering do Windows nos dois novos servidores disponibilizados;
+++ Configuração do cluster Windows;
+++ Configuração do Storage Spaces Direct com os discos apresentados de ambos os storages (Site A e Site B);
+++ Criação do pool e dos volumes para usar no SQL Server;
+++ Instalação do SQL Server 2019 em ambos os nodes;
+++ Backup / Restore das bases do SQL Server 2014 para o SQL Server 2019 para validar tempos e procedimentos;
+++ Criação de replicação via logshipping do SQL Server 2014 para o SQL Server 2019 para a virada com mínimo downtime;
+++ Testes de benchmarking / failover / disaster recovery;
+++ Virada foi realizada parando produção, aplicando últimas transações pendentes e “abrindo” o banco no 2019;
+++ Para ter o mínimo de problemas com a aplicação, mantemos o mesmo nome de listener e ip do cluster. Com isso, só fizemos o switch entre os clusters e as aplicações conectaram, sem precisar mudar as strings de conexão.
Após a migração, fizemos uma validação da velocidade entregue, tanto em leitura quanto em escrita, entre o ambiente antigo e o novo.
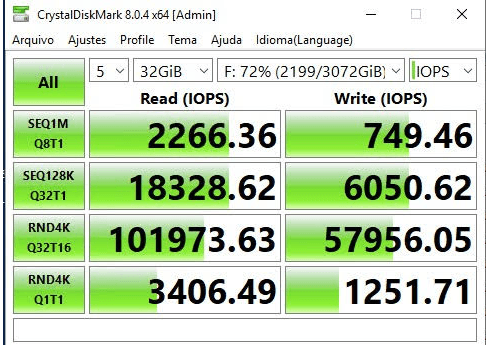
No teste, usamos a ferramenta CrystalDiskMark e validamos com um arquivo de 32 GB.
Para o SQL Server, a métrica importante é a RND 4K Q32T16, que simula pequenas operações constantes e simultâneas, o mais próximo de simular um ambiente OLTP.
+++ Cluster SQL 2014 com storage compartilhado alcançava 100K IOPS em leitura e 22K IOPS em escrita.

+++ Cluster 2019 com S2D – conseguimos um resultado de 100K IOPS em leitura e 57K IOPS em escrita, quase triplicou o valor para escrita.
Além de entregar uma versão atualizada do SQL Server para o principal sistema da fábrica, que possui integração com o SAP, ainda melhoramos o plano de disaster recovery, garantindo alta disponibilidade entre os datacenters, e aprimoramos a entrega em performance dos discos.
Para saber mais sobre as tecnologias envolvidas:
Storage Spaces Direct overview
SQL Docs: What is an Always On availability group?
SQL Docs: Create a New Always On Failover Cluster Instance (Setup)