

escrito por Yan Cescon Haeffner
6 minutos de leitura

As data warehouses processing becomes cheaper, new tools starts to emerge along with ELT and the needs for automation. This is the first post of a series about data build tool and today we will break it down a little.
Information, especially facts or numbers, collected to be examined and considered to help decision-making, or information in an electronic form that can be stored and used by a computer.
The quote above is a formal definition of the most abundant, but yet kind of new, by-product of mankind: data. But wait, I’m not here to talk about the nail (there’s plenty of “data” about that), I’m here to show you a very useful hammer called data build tool, or dbt for acronyms fans.
If you are wondering why you should pay attention to new technologies on data transformation, notice that, by definition, data depends on prior validation to be considered useful, which means that even if you were able to collect, store and use all data in the world, as is, it does not guarantee that you could find the answer to all of your questions.
Golden Data

Photo by Zlaťáky.cz on Unsplash
Imagine data as a gold nugget: in its natural state it has some value, you could get some money by selling it as is but, most of the time, it won’t be useful since it may contain a lot of impurities. A refined gold bar, on the other hand, is a pure metal with very useful physical properties that can generate a lot of value to many kind of products. The exact same phenomenom occurs with data: once it has been properly processed you are now able to generate value (answers) for many kind of problems (questions), pure gold isn’t it?
So, that being said, even if the transformation process is a very important, and crucial, step to any data-driven business, why should we bother with new technology to apply that transformation? Ain’t my Apache enough?
The Rise of ELT

Photo by CHUTTERSNAP on Unsplash
Well, it was. With the reduction on prices and the improvement of storage integration of data cloud services, it became a lot cheaper to keep and process all the data inside the same storage structures (like data warehouses). That shifted the data pipeline strategy from ETL to ELT, which means that, now, companies are able to get all the data first and then transform it as needed, allowing changes on data models while keeping the historicals (raw data) available.
Now imagine that you have tons of data being generated every day, and you need to process and transport all of that while applying different transformation rules and with the least amount of human interference as possible (reducing the amount of problems on your output). Also, after some time you end up needing to make some changes on some of your models and, because of that, a new documentation needs to be done, and new data lineage needs to be tracked. Quite a lot of human error possibilities, right?
Data Build Tool, dbt, is a command line tool that is responsible for the T on ELT procedures: the data transformation process.

DBT as depicted by https://blog.getdbt.com/what-exactly-is-dbt
It allows analytics (and data) engineers to automate repetitive tasks within the transformation process of ingested data, like: documentation, testing and deployment. In a sense, the data team would be able to pay more attention (and invest more time) to effectively deliver value with increasingly complex data transformation instead of doing lots of repetitive “paper work”.
As implicitly pointed before, the possibility to process data from within the data warehouse also creates the urge of a tool to automate as much as possible of those tasks in order to avoid errors and unnecessary effort waste.
How it works
You may be wondering why you would need a command line tool if you are going to process things inside your DWH, right? Well, the thing is that dbt is a python based software that has both a compiler and interpreter shipped with it.
The compiler allows the engineer to focus on direct SQL SELECT statements with Jinja templating to create unique, optimal and flexible models, using variables to refer to dependencies and avoiding the need to order things up.
It means that a dbt model is a SELECT statement (with a few special features if needed) so, even if you’re creating/updating a table or a view (check out the materialization section), it structure will look like this example from Fishtown Analytics:
After the model is done, dbt converts everything to pure SQL scripts and creates a Directed Acyclic Graph that handles the ordering of execution of each script. And the best part of it? It automatically takes care of converting things up to optimal SQL expressions based on the data engine you are using (like Redshift, Snowflake and Big Query). Not a fan of self-service macros? You’re always allowed to overwrite/create macros as needed.
And you can always refer to the documentation to find out that, most of the time, the sky is not always the limit.
The simplicity of dbt as a standalone command line tool also allows engineers to build containerized solutions while using Docker, Kubernetes and services like Fargate and so on…
But wait, there’s more!
Sourcing
One thing that I’ve first asked myself when I started working with dbt was: “will I have to model my whole DWH from scratch to use it?!”
Thankfully the answer is no. By defining a schema/table as a source in your dbt project, you are able to attach existing data to your model without the need to refactor everything from scratch. Also, by doing that, you add another, very useful, layer on your data model: source testing.
By moving from ETL to ELT procedures you may end up skipping some validations when loading things to your DWH, and that’s precisely where dbt excels, allowing you to define data tests that should be executed on your source (raw) data before moving on to run your transformations. This feature alone is able to build a lot of value (and trust) for your data team, because now we have some control over the data we are ingesting without the need to build complex extracts and loading processes.
Testing
As mentioned above, testing aggregates a lot of value and reliability to your data so, because of that, you should really consider using that part of dbt.
The tool comes with some standard tests definition for your data and always allows you to build your own test scripts (also in SQL/Jinja) as needed.
You can also describe the severity of your tests, allowing the pipeline to warn for possible faulty pieces or even shut down the running model in case of invalid data (or invalid conditions, like uniqueness of IDs or something).
It’s also possible to store failures into a table, allowing the data team to understand what went wrong with the expected model behavior right from the DWH.
Finally, dbt allows you to describe your model and tests, bringing us to the most time consuming task (and ultimately important) of any engineering team: documentation.
Automated documentation
Personally, I think that this feature is the one that ultimately convinced me (and my team) to start using dbt. To me, there’s nothing worst than burning a lot of energy working on mining gold out of raw data and finding out that, after it’s done, you still need to look back to everything you have done and write it down so your team can absorb and understand it all.
And sometimes, the documentation of a task can consume more time than working on the task itself, so, it’s definitely something that we should take into consideration when looking for handy tools.
What dbt does is to put together all the descriptions you’ve made along your model/sources/tests definitions, and build a really nice UI on a static (and local) web page to display all of that. Plus, it also generates a beautiful data lineage so that your team can understand what’s being consumed and what is consuming things on your model.
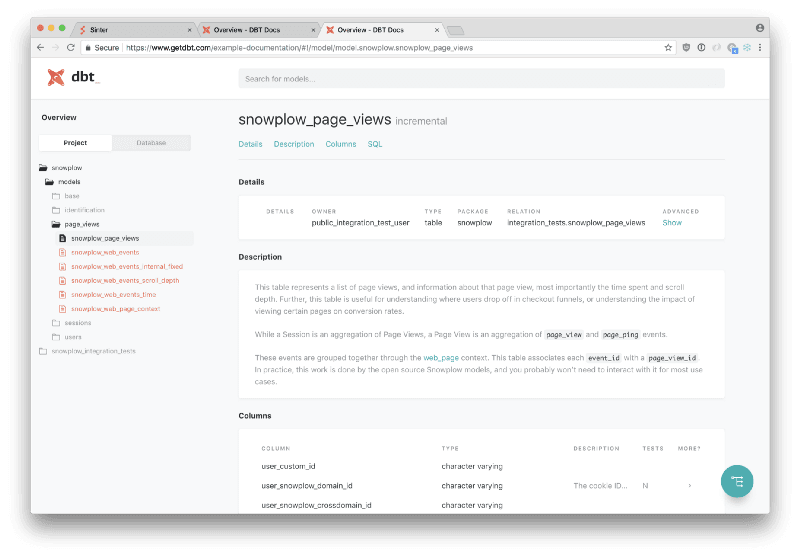
Documentation page example from Using dbt docs (getdbt.com)
And since dbt generates a complete web page for the documentation, you can share it as needed with your team in order to share the knowledge behind the new/refactored data structure, just like with this example page from Fishtown Analytics.
Now that we talked about dbt, you may (or may not, totally fine) be excited to start implementing it on your data pipeline, right?
Well, since there’s a lot of steps to do that, I’ll talk about a possible dbt implementation with a small demonstration on the next post!
Meanwhile, you should check out for Fishtown Analytics documentation on dbt since it covers everything we talked about today in much more technical details!
Thank you and stay tuned!