
Writen by Augusto Klaic, Software Engineer, in 07/06/2022
6 minutes of reading
Some thoughts on a Philosophy of Software Design
Yes, the book and not my daydreams

Hello there! This text is meant to be an introduction to the book “Philosophy of Software Design” written by John Ousterhout to encourage more developers to read it. Here you will find a compilation of thoughts about my reading of the book mixed with a resume of some chapters. GLHF!
Complexity —
“Complexity is anything related to the structure of a software system that makes it hard to understand and modify the system. “ — John Ousterhout

John introduces to us in his book two approaches to fight complexity. The first one is to make code more obvious and simpler by removing special cases not needed in the code. The second approach is the modular design, like the name suggests it’s to divide and develop the software into parts called modules that have individual responsibilities and are independent of other modules, so the developers can work just knowing the specific module they are. Those concepts are important because while software evolves and gets bigger it starts to get more complex, and it’s normal because more features are being added to it over time. So it’s important to encapsulate and work with modules.
To diagnose our application as complex the book brings three important symptoms that, when you are developing, you can look up and see if they are occurring during your code processes:
+++ Change amplification: basically when a seemingly simple change causes a huge modification in many parts of the system or a refactor. As an example, we can have a string parameter that is used in many parts of the code in its literal form — “some string” — and at a certain moment you have to change that parameter, so you will have to go on every part of the code that it is used and correct to the new one.
+++ Cognitive load: in a few words, it is the amount of knowledge about the system a developer has to have to complete a task. So if the system has a lot of dependencies or depends on another part of the system to work, the developer making changes in it will have to know those dependencies and other parts to not cause problems and bugs to the existing software instead of just knowing what he has to do.
+++Unknow unknows: as the philosopher Socrates in the ancient Greek once said: “I just know that I know nothing”, this complexity symptom is related to the developer not knowing exactly what change he has to do to solve the problem or what information he must have to carry out the task successfully. The developer doesn’t know if the task he got is a task of minutes of developing or it is a task of hours, days, weeks… This is by far the worst symptom.
If some of them appear to you, know that you will have to make some changes because the more your application grows, the more headache you will have to make changes and correct bugs in the future. Complexity isn’t caused by one problem or error, it is the sum of every little tech debt or bad design decision that is taken from the start.
Working Code Isn’t Enough —
Tactical Programming VS. Strategic Programming

In software development, we are always being pressured by project leaders or stakeholders to deliver more and faster, so the timebox and the cost of the project reduces. The book brings a duality in this situation about fast delivery and code quality. How to attend both objectives if they end up conflicting?
In this duality in the power, we have two approaches: tactical and strategic programming. John introduces in this part of the book a term called: “Investor mindset”, which basically means that using the metaphor of an investor, there will be some “lose time” in the present moment designing the best solution but in the future that time will be retrieved back on the form of complexity reduction, facilitating development enjoying the advantages of what was done. The investor mindset is the personification of strategic programming.
Putting in a day-by-day perspective, 100% sure that the strategic programming approach is better because there is no rush or competition to see who deliveries more, so taking the time to design the best possible solution is worthy, but there are some situations that the time for designing and thinking about a solution is scarce. Like a live demo of the product that occurred some problem or when participating in a hackathon. In those situations, working code is all you want. Sometimes is fine to think tactically. The problem with tactical programming is that it is short-sighted, there is no thought about the future or planning, it is focused on the immediate correction and that can increase the complexity in the long term because there is no design thinking of how that piece of code will fit into the codebase.
Taking some conclusions based on the book, the longer the project the more effective the strategic programming approach will be. Using the hackathon example that is a one or two days long project, the tactical approach is good because the objective is to get the happy path of the MVP working as fast as possible. This image represents well the examples:
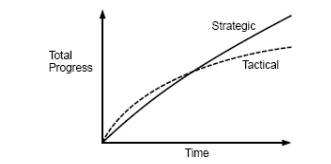
tactical vs strategic programming
Deep Modules and Information Hiding —
The most complex things we hide deep inside our ~heart~ modules!

At the start of the book, we are introduced to the modular design, that every part of the system must encapsulate a part of the business logic and be relatively independent. Adding to that, this part of the book defines how a good module should be: divided into interface and implementation, being the interface way more simpler than the implementation. The interface contains the signatures of the methods that consist of the name of it, its parameters, the return value, and, if applicable, the exceptions that are thrown. And the implementation is the part where those methods are written down with their business logic.
Another good point is the concept of abstractions. When used in the code, it can easily (and here I say easily in a manner of speaking) hide “unimportant” details of the implementation like variables, business logic, and sensitive information. It is a simplified view of the entity. They are also known as Interfaces in the world of software. They facilitate the use of libs or services to the others users that were not involved in the development of it.
About this topic, the book shows the difference between a deep module and a shallow module. Basically, a perfect module has a concise interface (less cost of complexity) and covers several functionalities (more benefits). A deep module helps in hiding information because while its interface offers only specific tools to be used like methods signatures, the implementation remains hiding all the important processing. Another good observation is that those methods of the interface are generic and can be applied to a lot of business logic raising the possibilities of usage.
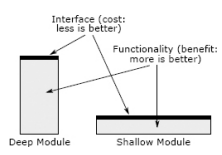
Last paragraph represented
Information hiding is another important topic to the author John because it helps to reduce the overall complexity in two ways:
+++ Simplifying the interface to a module, reducing the cognitive load on devs who uses the module;
+++ Making it easier to progress on the software development, because if the information is hidden there are no dependencies on it facilitating design changes;
A good way of achieving information hiding is through the functionalities of private and protected methods and variables, although it can still be accessed through getter and setter methods, the best way is when all the information is hidden within a module, being irrelevant to the user that doesn’t even know that the methods and alike were used. And of course, information hiding only makes sense when the information that is being hidden is not needed, otherwise, it could not be accessed.
General-Purpose and Pulling the complexity Downwards —
Generify-it… It’s more important having a simple interface then a simple implementation
One of the best chapters (for me) in the book, because I could see and apply it to my job daily. This chapter talks about the benefits of generifying the code to solve a broad range of problems. It reinforces the Investor Mindset discussed earlier here. Using a general-purpose approach means essentially: REUSE. The solution developed can be applied to some business problems and also to others with the same efficiency, making the module or class simpler with fewer methods and less complexity increasing code quality and separation of responsibility which leads to better information hiding.
Of course that generalizing is not a programming rule, sometimes it’s hard to run away from a special purpose. It’s not wrong and has some cases that are so specific that require a unique solution. So just do the special-purpose method to handle the problem but be cautious because only creating special-purpose solutions can create complex interfaces and transform the reuse of code into a hell.
John also points out that developing general-purpose code will make the classes deeper, which brings back the already mentioned benefits and opens the opportunity of pulling the complexity to the inner parts of the class. This can free the user of the interface from facing (or causing) problems while trying to use the methods of this interface, when pulling down the complexity it became invisible to the user, which will stay on the interface level. The counterpart of this is that now you, the developer, will have to solve the problems that were reaching the user.
Another discussion similar to this topic of generalization is the part of the separation of functionalities. All general-purpose type code should be put apart and separated from the special-purpose code, because in that way the general-purpose mechanism can be reused by various special-purpose mechanisms, reducing complexity and duplication.
Exceptions —
One does not simply to handle an exception — Boromir, son of Denethor.
Let’s start with the book’s premise: “exceptions cause complexity”, agreeing or not this is a fact. Think about how many special conditions will be caused by adding one exception. Two unit tests at least, one error mapping for responses, the error handler itself and this is just what I could think in one minute writing this.

But wait, don’t rush to delete all of your code’s exceptions. There are some cases where they are very useful and important. The point that John talks on his book is to reduce the places where exceptions must be handled in the code because every time an exception is thrown it changes the normal flow of the code, adding more complexity to it.
A very clear way of explaining the idea that John brings in this chapter is “define errors out of existence”, which basically states to code in a way that exceptions are not needed in the majority of the cases. One way to achieve this is to use default returns on methods to substitute exceptions, like everything out of the “happy path” returns a certain default value.
The book also brings two more possibilities of reducing complexity by reducing exceptions:
+++ Masking exceptions: Consists in handling exceptions in the inner level of the system so the higher levels don’t need to be aware of it, this pulls the complexity downwards and makes the class deeper.
+++ Exception Aggregations: As the name suggests, exception aggregations are about handling many exceptions with a single piece of code, not needing to add different treatments for every single case. Thus creating a ”general-purpose” mechanism to handle exceptions.
Comments —
// This is a comment
Comments are another very good topic in this book. Everybody already listened to someone saying: “The code must talk by itself, don’t use comments!”, this is bullshit. Yeah, kind of. It’s understandable the concept of code talking by itself, this relates to good variables, classes and methods names, good logical organization, clean code and etc. But comments are very important and they bring a lot of benefits for those who code and for those who use the code.
Even if the code is the most obvious, sometimes a comment can save the day. The developer who wrote the code doesn’t know all the possible questions that might come from the developer who uses the code. A comment telling what the method does with the parameters it receives or what happens when receiving an unwanted parameter is always good. The comment can be seen as an interface to what is being commented because it brings an abstraction over the code giving a simplified explanation of it.
The entire book is about complexity and how to reduce it, so in this chapter, the subject comment is introduced as a mechanism of explanation of the code in our language (Portuguese, English…) so everyone can get the functionality of the commented code, not only a Java developer will understand a Java method does, but a Golang developer can get it and even a Product Owner can understand it. This is the magic behind comments, it takes out the complexity of understanding a string.split(“a”, 2) to “separate a string in N substrings with a size of 2 characters given a separator delimiter”.
In the example above if the person is not a Java developer he wouldn’t know exactly what the method is meant to do without testing it, but when reading the documentation or comments the functionality is clearly explained.
Conclusion —
This book is an amazing first tech reading for every dev, John does an excellent work explaining the concepts he brings in the book, and ally with that he shows arguments in favor and against almost every topic. The book is great in its proposal and can help you think differently when coding and make you pay attention to things that before reading was being ignored. Reading a “Philosophy of software design” makes me have a good time that I didn’t experience for a long time, I didn’t have the habit of reading, and now I am trying to change that and continue to read other books!
Recommended!!!
Ficamos felizes que você tenha interesse em nosso conteúdo.
Preencha os campos abaixo e em breve você estará recebendo novidades de design + inovação + software em seu e-mail.
Suas informações são armazenadas com segurança e serão utilizadas apenas para envio de conteúdo. Você poderá se descadastrar de nosso mailing a qualquer momento através do link presente no rodapé dos nossos e-mails.
